
This edition contains the following articles:
- Coming Soon: Heme & Non-Heme Iron, Percent Calories from Added Sugars, and Updated and New Foods in the 2025 version of the NCC Food and Nutrient Database and NDSR
- Using NDSR to Assess Ultra-Processed Food Intake
- Caution in Using Individual Nutrients (NTRNs) in NDSR
Coming Soon: Heme & Non-Heme Iron, Percent Calories from Added Sugars, and Updated and New Foods in the 2025 version of the NCC Food and Nutrient Database and NDSR
We anticipate releasing the 2025 versions of the NCC Database and NDSR later this summer, and both now include heme and non-heme iron thanks to funding from the National Cattlemen’s Beef Association to support this work. In response to your requests, we have also added Percent Calories from Added Sugars.
We let you know in our last News Bite that baby foods and infant formulas have been updated for the 2025 versions of the NCC Database and NDSR. Meat alternative products from the following popular brands have also been updated:
- Beyond
- Gardein
- Good Catch
- Impossible
- MorningStar
- Quorn
- Tofurky
- Worthington Plant Powered
In addition to updates to the existing database, our team has added a variety of new foods including carnitas, barbacoa, kalbi, African peanut soup, aloo palak, candied ginger, Liberian check rice, massaman curry, mixed berries, stuffed pork chop, and Szechuan beef.
As a reminder, the latest version of NDSR is included as a component of your annual NDSR support. Any clients with up-to-date support at the time of the NDSR 2025 release will receive access to the updated software. Not sure of your support status or want to reinstate your support for another year? Send us an email at NDSRhelp@umn.edu to learn more!
For our NCC Food and Nutrient Database Licensing clients, those with an agreement for the 2025 files will receive an invoice in the coming weeks unless you have pre-paid. Files will be sent per your licensing agreement. Any questions can be directed to your licensing contact or NDSRhelp@umn.edu.

Using NDSR to Assess Ultra-Processed Food Intake
We have heard from some of you that you are interested in identifying ultra-processed foods in your dietary data so that you can assess level of intake of foods considered ultra-processed according to the NOVA classification system. While NDSR does not classify foods into NOVA classified categories, researchers can carry out this type of classification of foods entered into NDSR dietary recalls, records, or menus. One way to do this with your NDSR output data files is to identify the unique food IDs in output file 02 and then assign a classification level to each food based on resources such as the NCC Database Food Group ID and ingredient statements for restaurant and packaged foods. If you are interested in more details on this potential approach for classifying foods in your NDSR dietary data, see the corresponding FAQ on the NCC website.

Caution in Using Individual Nutrients (NTRNs) in NDSR
It has come to our attention recently that some NDSR users are adding or subtracting individual nutrients (NTRNs) to User Recipes in NDSR. This is being done to create User Recipes for commercial products that match the Nutrition Facts panel. We advise against doing this for the reason described in the paragraph that follows.
The NTRNs in the database were designed primarily for users who wish to create a User Recipe for a food for which nutrient values were determined by chemically analyzing the food in a laboratory setting. Beyond this intended use, the NTRNs have a limitation. The limitation is that NTRNS do not relate to any other nutrients or food components in the database. For example, if you add total protein to a User Recipe using the NTRN for protein, you are adding a specific amount of protein, but not adding calories or any of the individual amino acids associated with that protein. Another example is the lack of relationship between different forms or units for a nutrient. For example, if the NTRN for vitamin A in International Units is used to add vitamin A to a food, the other forms of this nutrient (e.g. vitamin A in Retinol Activity Equivalents and Retinol Equivalents) are not added.
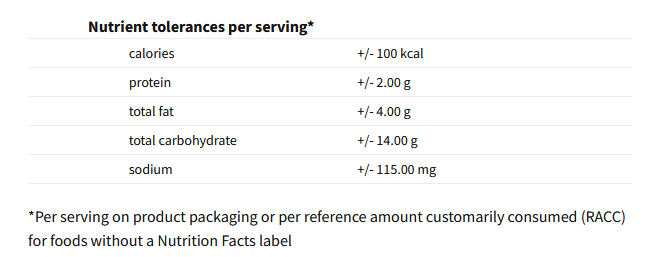
Please note that if you are trying to adjust the micronutrients of a food, you may want to use the components for food fortification in NDSR, which we refer to as SFORs. For example, if you want to make a User Recipe for a food to better match a product label, you could start with an NDSR food that is a close match (e.g. Cheerios). Then add or subtract one of the components for food fortification, such as calcium or vitamin C. We also advise using SFORs with caution, especially when subtracting an amount, as the danger is a net negative value for the food. However, the SFORs will more appropriately maintain their relationships with other nutrients in the database as shown below.
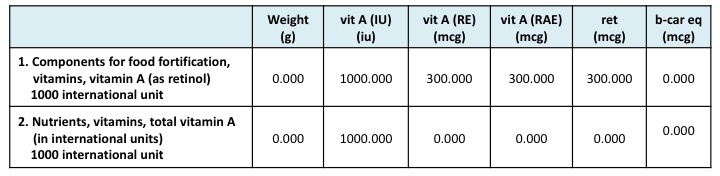
The next image shows the difference between the SFOR calcium (first search result) and the NTRN calcium (second search result).

You are welcome to contact us with questions about the difference between using NTRNs and SFORs and what might be best for your work. Contact us at NDSRhelp@umn.edu.